
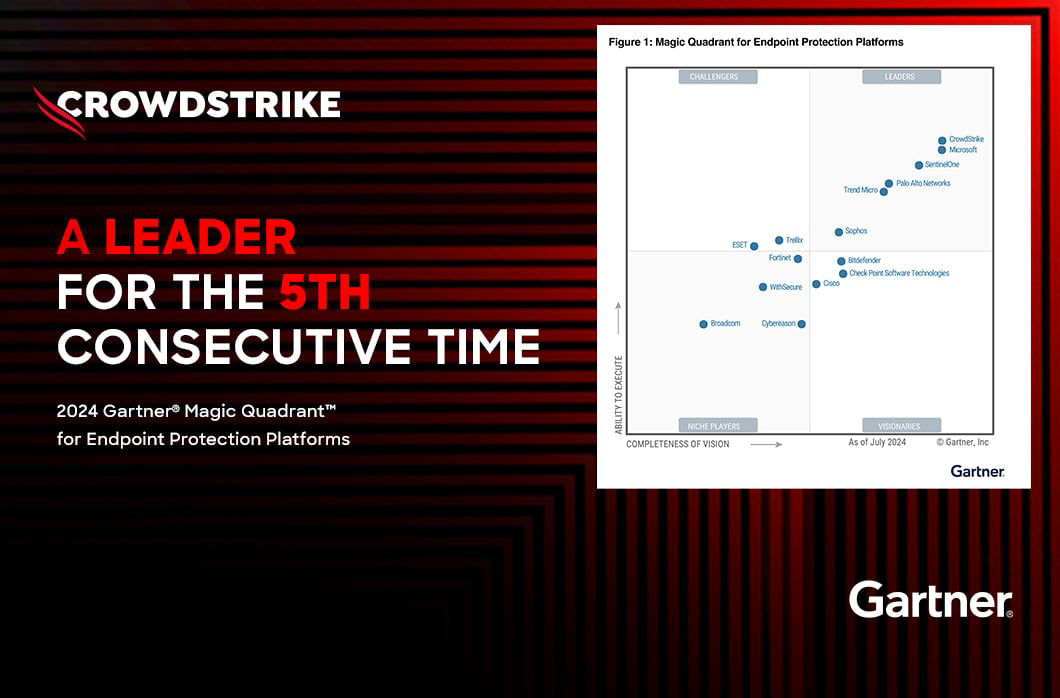



![Qatar’s Commercial Bank Chooses CrowdStrike Falcon®: A Partnership Based on Trust [VIDEO]](https://assets.crowdstrike.com/is/image/crowdstrikeincstage/Edward-Gonam-Qatar-Blog2-1)
































In Part 1 of this two-part blog series, we addressed binary exploitation on Windows systems, including some legacy and contemporary mitigations that exploit writers and adversaries must deal with in today’s cyber landscape. In Part 2, we will walk through more of the many mitigations Microsoft has put in place.
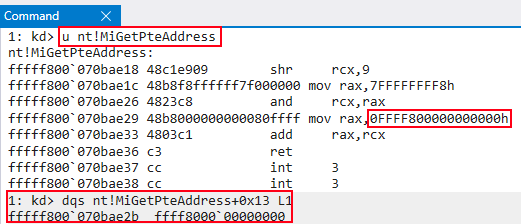 Figure 1: Page table de-randomization via
Utilizing an arbitrary read primitive, it is possible to extract the base of the page table entries utilizing this technique. With the base of the PTEs in hand, the aforementioned trivial calculation primitive remains valid.
Note that Windows 10 1607 (RS1) not only randomized the PTE base address, but the base address of 14 other regions of kernel memory as well. While the PTE base was the most significant change, these other randomizations also helped curb certain kinds of kernel exploits, which are outside the scope of this post.
Figure 1: Page table de-randomization via
Utilizing an arbitrary read primitive, it is possible to extract the base of the page table entries utilizing this technique. With the base of the PTEs in hand, the aforementioned trivial calculation primitive remains valid.
Note that Windows 10 1607 (RS1) not only randomized the PTE base address, but the base address of 14 other regions of kernel memory as well. While the PTE base was the most significant change, these other randomizations also helped curb certain kinds of kernel exploits, which are outside the scope of this post.
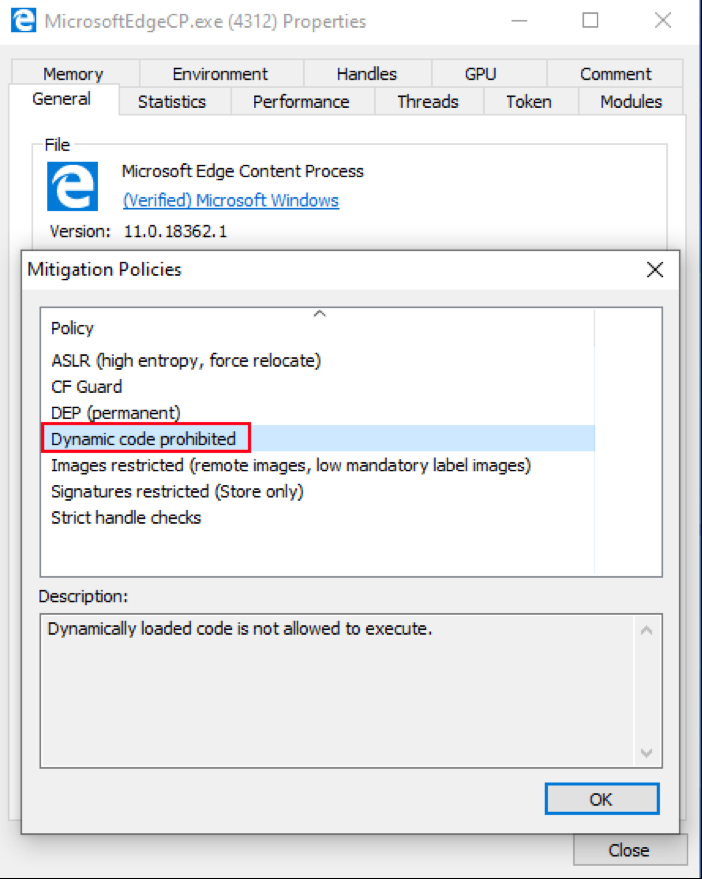 Figure 2: A process protected by ACG
ACG prevents existing code, such as malicious shellcode that waits to be made
Figure 2: A process protected by ACG
ACG prevents existing code, such as malicious shellcode that waits to be made 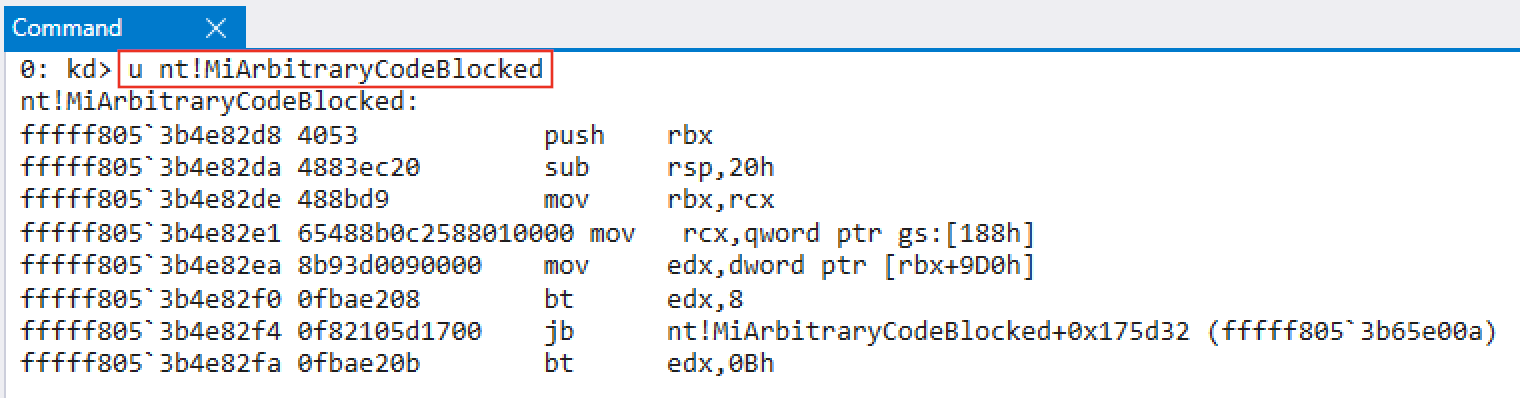 Figure 3:
The
Figure 3:
The 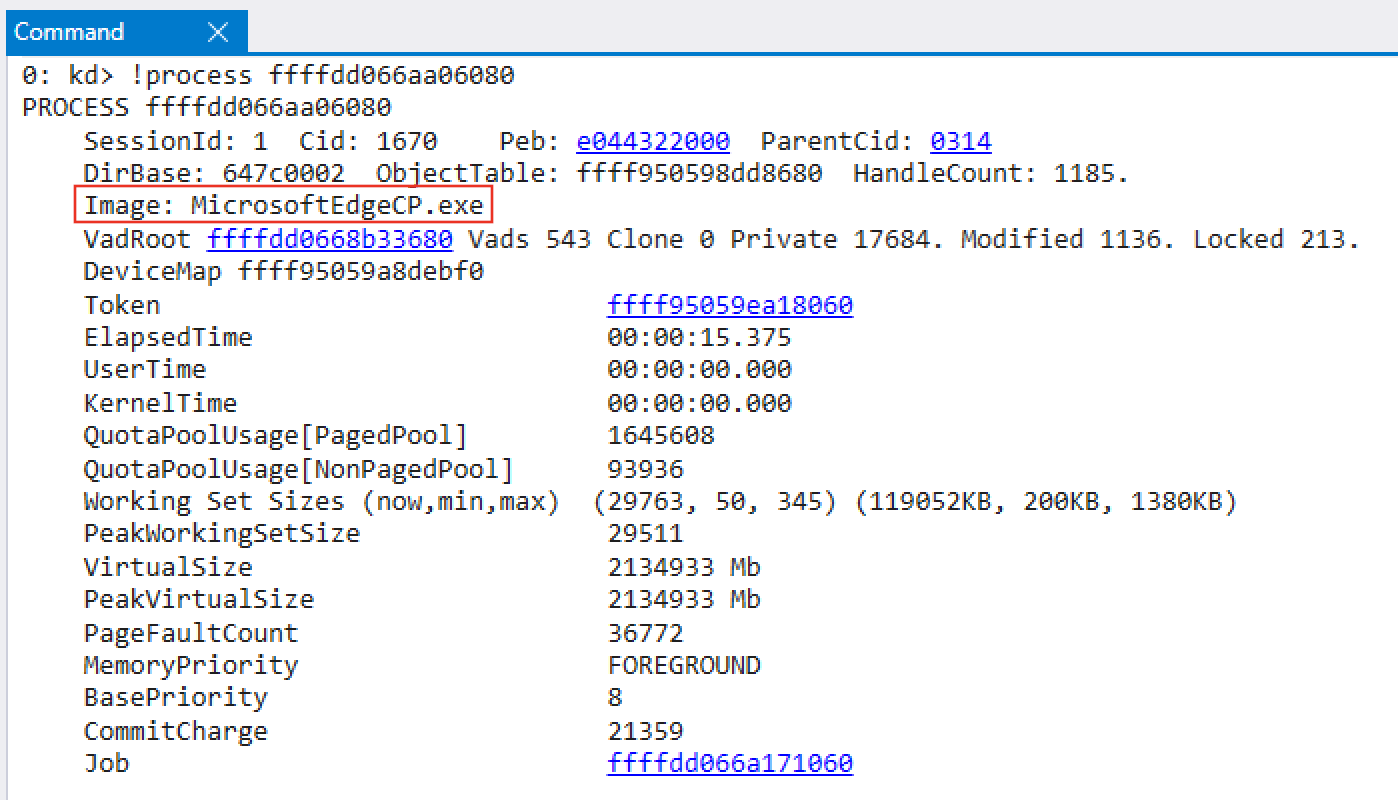 Figure 4: MicrosoftEdgeCP.exe
Referencing the
Figure 4: MicrosoftEdgeCP.exe
Referencing the  Figure 5:
At this point, if dynamically created executable code is created for a process and this flag is set, a
Figure 5:
At this point, if dynamically created executable code is created for a process and this flag is set, a 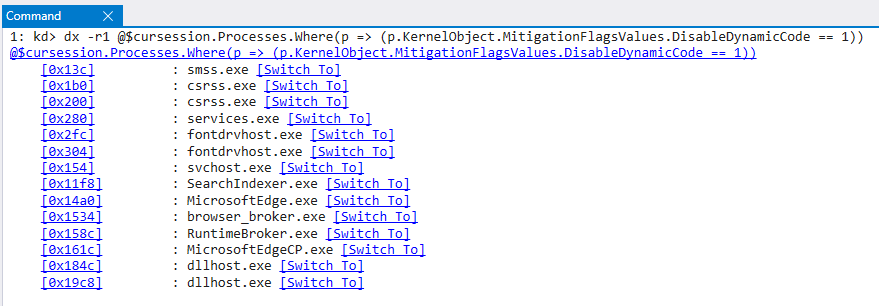 Figure 6: A list of processes with ACG enabled
Although the bypasses for ACG are not plentiful, logic led researchers and adversaries to attack JIT (just-in-time) compilers. JavaScript is an interpreted language — meaning it is not compiled into direct machine code. Instead, JavaScript utilizes “bytecode.” However, in certain cases, JIT compilers are used by browsers to dynamically compile JavaScript bytecode into actual machine code for performance benefits. This means that by design, JIT compilers are always creating dynamically executable code. Due to this functionality, ACG isn’t compatible with JIT and has only had limited power inside of Edge before Windows 10 1703 (RS2).
Alex Ionescu explained in a talk at Ekoparty that prior to the 1703 (RS2) update, Edge had one thread responsible for JIT because of ACG. Since JIT isn’t compatible with ACG, this “JIT thread” did not have ACG enabled — meaning if compromising this thread was possible, it would then be possible to circumvent ACG. To address this, Microsoft created a separate process for Edge JIT compilation entirely in Windows 1703 (RS2). In order for an Edge Content process (a non-JIT process) to utilize JIT compilation, the JIT process utilizes a handle to an Edge Content process in order to perform JIT work inside of each non-JIT process.
ACG has a “universal bypass” in that researchers and adversaries can stay away from code execution entirely. By utilizing code reuse techniques, it is possible to write an entire payload in ROP, JOP or COP, which will “adhere” to ACG’s rules. Instead of using code reuse techniques to return into an API, an option would be to just use it to construct the entire payload. Additionally, compromised browsers will need to utilize a full code reuse sandbox escape. This is not ideal, as writing payloads in ROP, JOP or COP is very time-consuming.
Figure 6: A list of processes with ACG enabled
Although the bypasses for ACG are not plentiful, logic led researchers and adversaries to attack JIT (just-in-time) compilers. JavaScript is an interpreted language — meaning it is not compiled into direct machine code. Instead, JavaScript utilizes “bytecode.” However, in certain cases, JIT compilers are used by browsers to dynamically compile JavaScript bytecode into actual machine code for performance benefits. This means that by design, JIT compilers are always creating dynamically executable code. Due to this functionality, ACG isn’t compatible with JIT and has only had limited power inside of Edge before Windows 10 1703 (RS2).
Alex Ionescu explained in a talk at Ekoparty that prior to the 1703 (RS2) update, Edge had one thread responsible for JIT because of ACG. Since JIT isn’t compatible with ACG, this “JIT thread” did not have ACG enabled — meaning if compromising this thread was possible, it would then be possible to circumvent ACG. To address this, Microsoft created a separate process for Edge JIT compilation entirely in Windows 1703 (RS2). In order for an Edge Content process (a non-JIT process) to utilize JIT compilation, the JIT process utilizes a handle to an Edge Content process in order to perform JIT work inside of each non-JIT process.
ACG has a “universal bypass” in that researchers and adversaries can stay away from code execution entirely. By utilizing code reuse techniques, it is possible to write an entire payload in ROP, JOP or COP, which will “adhere” to ACG’s rules. Instead of using code reuse techniques to return into an API, an option would be to just use it to construct the entire payload. Additionally, compromised browsers will need to utilize a full code reuse sandbox escape. This is not ideal, as writing payloads in ROP, JOP or COP is very time-consuming.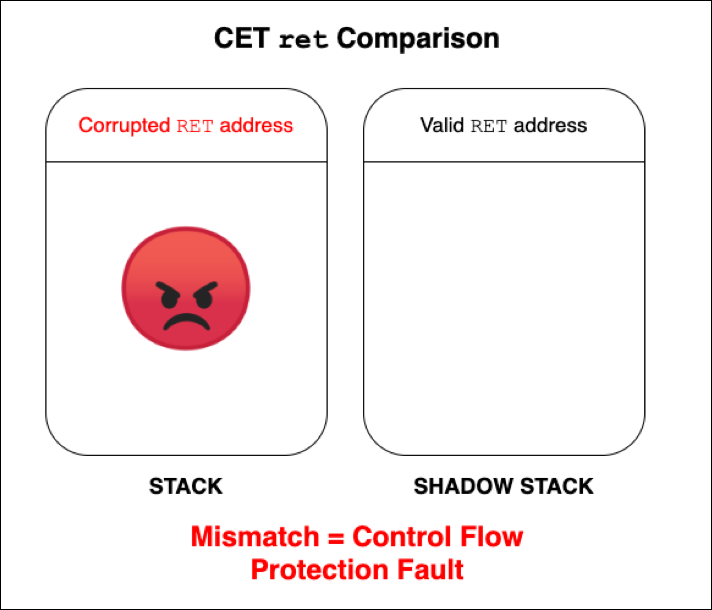 Figure 7: A look at a “pseudo” check of a return address through CET
Although CET, which is a part of the Intel Tiger Lake CPU family, has not hit mainstream consumer hardware, some possible bypasses have been conceptualized.
Figure 7: A look at a “pseudo” check of a return address through CET
Although CET, which is a part of the Intel Tiger Lake CPU family, has not hit mainstream consumer hardware, some possible bypasses have been conceptualized.
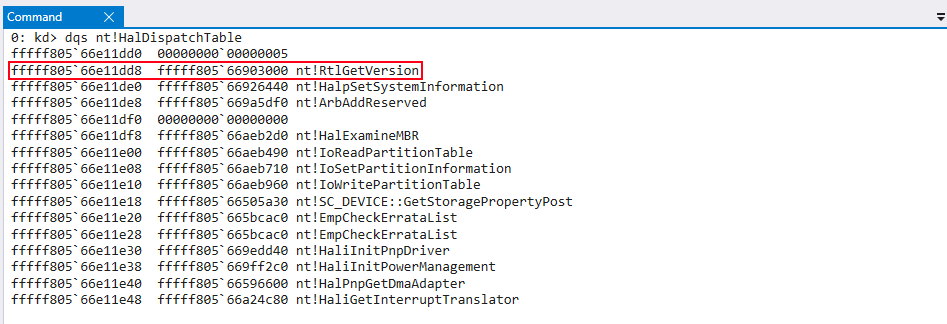 Figure 8: Just before reaching execution, the kCFG bitmap takes in the value of RAX, which will be
Figure 8: Just before reaching execution, the kCFG bitmap takes in the value of RAX, which will be 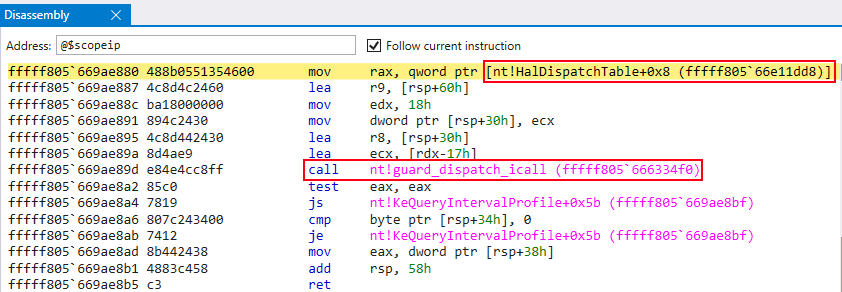 Figure 9: Pointer to
Figure 9: Pointer to
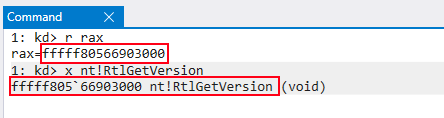 Figure 10: Actual value in RAX is
The bitwise checks occur and the function call is still allowed to occur, even though
Figure 10: Actual value in RAX is
The bitwise checks occur and the function call is still allowed to occur, even though 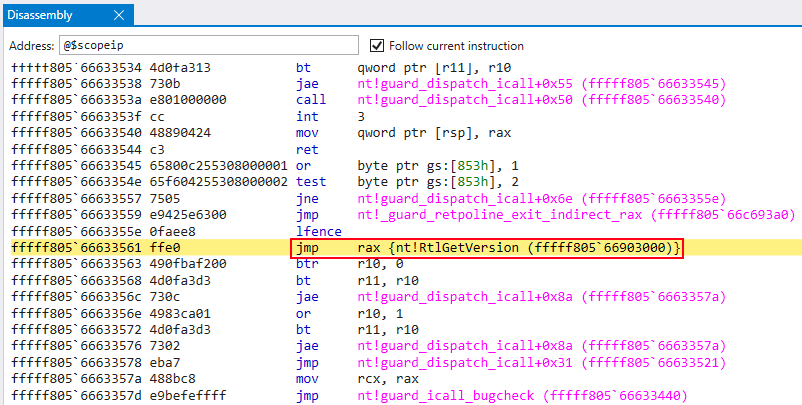 Figure 11: A
Figure 11: A
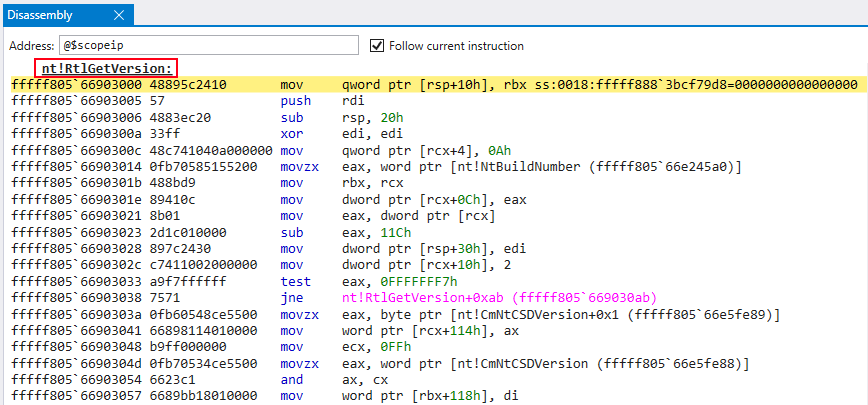 Figure 12: Call to
Although CFG does thwart some indirect function calls to overwritten functions, it is still possible with crafted function calls to make calls with malign intent.
XFG addresses this lack of robustness, as mentioned by David Weston of Microsoft. In David’s talk at BlueHat Shanghai 2019, he explains that XFG implements a “type-based hash” of a protected function, which is placed 0x8 bytes above a call to one of the XFG dispatch functions.
Figure 12: Call to
Although CFG does thwart some indirect function calls to overwritten functions, it is still possible with crafted function calls to make calls with malign intent.
XFG addresses this lack of robustness, as mentioned by David Weston of Microsoft. In David’s talk at BlueHat Shanghai 2019, he explains that XFG implements a “type-based hash” of a protected function, which is placed 0x8 bytes above a call to one of the XFG dispatch functions.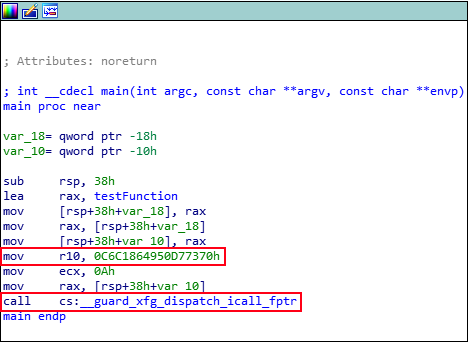 Figure 13: An XFG hash is loaded into
If an XFG function hash, which is generated by the compiler, is not vigorous and complete, hashes may not be unique. This means that If the sequence of bytes that makes up the hash is not unique, the opcodes that reside 8 bytes under the hash may contain the same bytes, when calling into the middle of a function, for instance. Although not likely, this may result in XFG declaring an overwritten function is “valid” because the comparison between the hash and the function, when disassembled into opcodes, may be true — resulting in XFG being bypassed. However, the compiler team has specifically implemented code to try to avoid this from happening. Similarly, because the hashing for C functions uses primitive types such as
Figure 13: An XFG hash is loaded into
If an XFG function hash, which is generated by the compiler, is not vigorous and complete, hashes may not be unique. This means that If the sequence of bytes that makes up the hash is not unique, the opcodes that reside 8 bytes under the hash may contain the same bytes, when calling into the middle of a function, for instance. Although not likely, this may result in XFG declaring an overwritten function is “valid” because the comparison between the hash and the function, when disassembled into opcodes, may be true — resulting in XFG being bypassed. However, the compiler team has specifically implemented code to try to avoid this from happening. Similarly, because the hashing for C functions uses primitive types such as 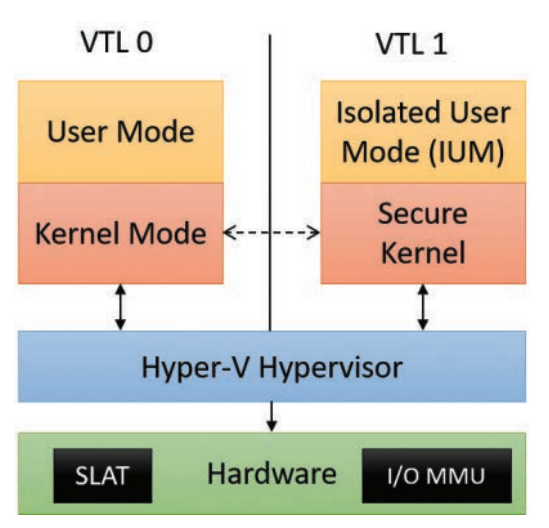 Figure 14: VBS implementation (Windows Internals, Part 1, 7th Edition)
VTLs, or Virtual Trust Levels, prevent processes running in one VTL from accessing resources of another VTL. This is because resources located within the normal kernel are actually managed by a more “trusted” boundary — VTL 1.
One of the main components of VBS mentioned in this blog is HVCI. HVCI is essentially ACG in the kernel. HVCI thwarts dynamically created executable code in the kernel. Additionally, HVCI prevents allocating kernel pool memory that is RWX, similar to ACG’s user mode protection against RWX pages via
Figure 14: VBS implementation (Windows Internals, Part 1, 7th Edition)
VTLs, or Virtual Trust Levels, prevent processes running in one VTL from accessing resources of another VTL. This is because resources located within the normal kernel are actually managed by a more “trusted” boundary — VTL 1.
One of the main components of VBS mentioned in this blog is HVCI. HVCI is essentially ACG in the kernel. HVCI thwarts dynamically created executable code in the kernel. Additionally, HVCI prevents allocating kernel pool memory that is RWX, similar to ACG’s user mode protection against RWX pages via
Modern Mitigation #1: Page Table Randomization
As explained in Part 1, page table entries (or PTEs) are very important when it comes to modern-day exploitation. You may recall that PTEs are responsible for enforcing various permissions and properties of memory. Historically, calculating the PTE for a virtual address was trivial, as the base of the PTEs were static for quite some time. The process for obtaining the PTE for a virtual address is:- Convert the virtual address into a Virtual Page Number (VPN), by dividing by the size of a page (usually 4KB)
- Multiple the VPN by the size of a PTE (8 bytes on 64-bit systems)
- Add the base of the PTEs to the result of the previous operation
PteBase.
On previous versions of Windows, the base of the PTEs were located at the static virtual address fffff680`00000000. However, after Windows 10 1607 (RS1), the base of the PTEs were randomized — meaning this process is now not so trivial.
One of the ways to bring back the “trivial” method of calculating the PTE for a given virtual address is to derandomize the base of the PTEs. The Windows API exposes a function called nt!MiGetPteAddress, which has been used in previous exploitation research by Morten Schenk in his BlackHat talk in 2017.
This function performs the exact same routine described above to access the PTE of a virtual address. However, it dynamically fills the base of the PTEs at an offset of 0x13 inside the function.
Figure 1: Page table de-randomization via nt!MiGetPteAddress+0x13Modern Mitigation #2: ACG
Arbitrary Code Guard (ACG), which was introduced in Windows 10, is an optional memory corruption mitigation meant to stop arbitrary code execution. Although ACG was designed with Microsoft Edge in mind, it can be applied to most processes. ROP, a well-documented technique to bypass DEP, is most commonly used to return into a Windows API function, such asVirtualProtect(). Utilizing this function and user-supplied arguments, adversaries and researchers are able to dynamically change permissions of the memory, in which malicious shellcode resides, to RWX. With ACG, this is not possible.
Figure 2: A process protected by ACGRWX, from being modified. If an individual has a read and a write primitive and has bypassed CFG and ASLR, ACG mitigates the ability to utilize ROP to bypass DEP via dynamically manipulating memory permissions.
Additionally, ACG prevents the ability to allocate new executable memory. VirtualAlloc(), another popular API to return into for ROP, cannot allocate executable memory for malicious purposes. Essentially, memory cannot dynamically be changed to PAGE_EXECUTE_READWRITE.
ACG, although a user-mode mitigation, is implemented in the kernel through a Windows API function called nt!MiArbitraryCodeBlocked. This function essentially checks a process to see if ACG is enabled.
Figure 3: nt!MiArbitraryCodeBlocked checks processes for the ACG mitigationEPROCESS object for a process, which is the kernel’s representation of a process, has a member of the union data type known as MitigationFlags that keeps track of the various mitigations enabled for the process. EPROCESS also contains another member known as MitigationFlagsValues that provides a human-readable variant of MitigationFlags.
Let’s examine an Edge content process (MicrosoftEdgeCP.exe) where ACG is enabled.
Figure 4: MicrosoftEdgeCP.exeEPROCESS member MitigationFlagsValues, we can see that DisableDynamicCode, which is ACG, is set to 0x1 — meaning ACG is enabled for this process.
Figure 5: DisableDynamicCode is set in an Edge content processSTATUS_DYNAMIC_CODE_BLOCKED failure is returned from the function check, resulting in a crash.
Additionally, it is possible to obtain a list of all running processes that have ACG enabled, by parsing all of the EPROCESSobjects.
Figure 6: A list of processes with ACG enabledACG has also been bypassed using Edge’s JIT structure. Ivan Fratic of Google Project Zero gave a talk at Infiltrate 2018 explaining that the way Content processes of Edge obtain handles to the JIT process is risky.
An Edge Content process utilizes the Windows API function
DuplicateHandle() to create a handle to itself that the JIT process can utilize. The issue with this is that the DuplicateHandle() function requires an already established handle to the target process with PROCESS_DUP_HANDLE permissions. Content Edge processes utilize these permissions to obtain a handle to the JIT process with a great amount of access, as PROCESS_DUP_HANDLE allows a process with a handle to another process to duplicate a pseudo handle (e.g., -1) that has maximum access. This would allow access to the JIT process from a Content Edge process where ACG is disabled. This could lead to a compromise of the system by utilizing Content Process to then pivot to the non-ACG-protected JIT process for exploitation.
These issues were eventually fixed in Windows 10 RS4, and obviously, Edge now uses the Chromium Engine, which is important to note also leverages ACG and an out-of-process JIT compiler.
Modern Mitigation #3: CET
Due to CFG not taking into account return edge cases, Microsoft needed to quickly develop a solution to protect return addresses. As mentioned by Joe Bialek of the Microsoft Security Response Center in his OffensiveCon 2018 talk, Microsoft initially addressed this problem with a software-based mitigation known as RFG, or Return Flow Guard. RFG aimed to address the problem by utilizing additional code in function prologues to push the return address of a function onto something known as a “shadow stack,” which contains only copies of the legitimate return pointers for functions and does not hold any parameters. This shadow stack was not accessible from user mode and therefore “protected by the kernel.” In the epilogue of a function, the shadow stack’s copy of the return address was compared to the in-scope return address. If they were different, a crash would ensue. RFG, although a nice concept, was eventually defeated by Microsoft’s internal red team, which found a universal bypass that came down to the implementation of any shadow stack solution implemented in software. Due to the limitations of any software implementation of control-flow hijacking, a hardware-based solution was needed. Enter Intel CET or Control-Flow Enforcement Technology. CET is a hardware-based mitigation that implements a shadow stack to protect return addresses on the stack, as well as forward edge cases such as calls/jumps through Indirect Branch Tracking (IBT). However, Microsoft has opted to use CFG (and XFG, which will be referenced later within this post) to protect forward edge cases instead of CET’s IBT capabilities, which works similarly to Clang’s CFI implementation, according to Alex Ionescu and Yarden Shafir. CET’s main talking point is its protection of return addresses, essentially thwarting ROP. CET has a similar approach to RFG, in that a shadow stack is used.When CET determines a target return address is a mismatch with its associated preserved return address on the shadow stack, a fault is generated.
Figure 7: A look at a “pseudo” check of a return address through CETModern Mitigation #4: XFG
Xtended Control Flow Guard, popularized as XFG, is Microsoft’s “enhanced” implementation of CFG. By design, CFG only validates if functions exist in the CFG bitmap — meaning that technically if a function pointer was overwritten by another function that existed in the CFG bitmap, it would be a valid target. Figure 8 below showshal!HaliQuerySystemInformation, has been overwritten with nt!RtlGetVersion.
Figure 8: nt!RtlGetVersionnt!RtlGetVersion instead of nt!HalDispatchTable+0x8 is loaded into RAX in preparation for the call to nt!guard_dispatch_icall Figure 10: Actual value in RAX is nt!RtlGetVersion, not the intended value of hal!HaliQuerySystemInformationjmp to RAX occurs, which contains the preserved value of nt!RtlGetVersion Figure 12: Call to nt!RtlGetVersion
XFG essentially takes the function prototype of a function, made up of the return value and function arguments, and creates a ~ 55-bit hash of the prototype. When the dispatch function is called, the function hash is placed 8 bytes above the function itself. This hash will be used as an additional check before control flow transfer.
Figure 13: An XFG hash is loaded into R10 before control flow transfer to the XFG dispatch functionvoid*, functions could potentially be overwritten with functions that have identical/similar prototypes.
Modern Mitigation #5: VBS and HVCI
In order to provide additional security boundaries for the Windows OS, Microsoft opted to utilize the existing virtualization capabilities of modern hardware. Among these mitigations are Hypervisor-Protected Code Integrity (HVCI) and Virtualization-Based Security (VBS). VBS is responsible for enabling HVCI and is enabled by default on compatible hardware after Windows 10 1903 (19H1) on “Secured Core” systems. It can also be turned on by default on Windows 10 2003 (20H1) systems for vendors that opt-in through system configuration, and if the hardware is modern enough to conform to Microsoft’s “Security Level 3” baseline. VBS aims to isolate user-mode and kernel-mode code by having it run on top of the Hyper-V Hypervisor. The following image from Windows Internals, Part 1, 7th Edition (Ionescu, et al.) outlines a high-level visual into the implementation of VBS. Figure 14: VBS implementation (Windows Internals, Part 1, 7th Edition)VirtualAlloc().HVCI leverages Second Layer Address Translation, known as SLAT, to enforce Enhanced Page Tables, or EPTs, which are additional immutable bits (in context of VTL 0) that set VTL 1 permissions on VTL 0 pages. This means that even if an adversary or researcher can manipulate a PTE control bit in kernel mode of VTL 0, the VTL 1 EPT bits will still not permit execution of the manipulated pages in VTL 0 kernel mode. Bypasses for HVCI could include techniques similar to ACG in data-only attacks. Staying away from executing code but instead utilizing code reuse techniques that don’t result in PTE manipulation or other forbidden actions is still a viable option. Additionally, if an adversary/researcher can leverage a vulnerability in the hypervisor, or in the secure kernel that operates in VTL1,
it may be possible to compromise the integrity of VTL 1.
Conclusion
By no means are the vulnerability classes and mitigations in these two blog posts an exhaustive list. These aforementioned mitigations are commonly enabled by default on many installations on Windows and must at bare minimum be taken into consideration from an adversarial or research perspective. Many adversaries commonly choose the “path of least resistance,” meaning sending a malicious document or a malicious HTA to an unsuspecting list of targeted users. Generally, this will be enough to get the job done. However, the counterpoint to that would be, does anything top a no-user-interaction, unauthenticated, remote kernel code execution exploit in a common service such as SMB, RDP, or DNS? Utilizing social engineering techniques relies on other uncontrollable factors such as security-aware end users who receive such phishing emails. Binary exploitation takes the people factor out of the code execution process, leaving less to worry about. A researcher or adversary may spend weeks or months to develop a reliable, portable exploit that bypasses all of the mitigations in place. An exploit, such as a browser exploit, may require one user mode arbitrary read zero-day to bypass ASLR; an arbitrary write zero-day to bypass DEP, CFG, ACG and other mitigations; a kernel arbitrary read zero-day to bypass kASLR/page table randomization from a restricted caller to prep the kernel exploit to break out of the browser sandbox; and a kernel arbitrary write zero-day for the kernel exploit. That is a total of four zero-days. Is the return on investment worth it? These are the questions research firms and nation-state adversaries must take into consideration.Sources
- https://downloads.immunityinc.com/infiltrate2018-slidepacks/ivan-fratric-bypassing-mitigations-by-attacking-jit-server/JIT%20Server.pdf
- https://youtu.be/gu_i6LYuePg
- https://www.blackhat.com/docs/us-17/wednesday/us-17-Schenk-Taking-Windows-10-Kernel-Exploitation-To-The-Next-Level%E2%80%93Leveraging-Write-What-Where-Vulnerabilities-In-Creators-Update.pdf
- What Makes It Page? The Windows 7 (x64) Virtual Memory Manager
- Windows Internals, Part 1, 7th Edition
- https://documents.trendmicro.com/assets/wp/exploring-control-flow-guard-in-windows10.pdf
Additional Resources
- Read the first blog in the series: “The Current State of Exploit Development, Part 1.”
- Learn more about how CrowdStrike can help your organization improve your cybersecurity readiness by visiting the CrowdStrike Services webpage.
- Read about CrowdStrike Red Team / Blue Team exercises by downloading the data sheet.
- Learn more about the powerful CrowdStrike Falcon®® platform by visiting the webpage.
- Test CrowdStrike next-gen AV for yourself. Start your free trial of Falcon Prevent™ today.


